Best practices / Recommandations pour la configuration de votre firewall
 25/06/2019 - 1 commentaire
25/06/2019 - 1 commentaire
Pour l'écriture de cet article, nous nous sommes basés sur les recommandations émises par l'ANSSI à travers ses publications Recommandations pour la définition d’une politique de filtrage réseau d’un pare-feu et Recommandations et méthodologie pour le nettoyage d’une politique de filtrage réseau d’un pare-feu.
Recommandations générales
La définition d'une politique de gestion d'un pare-feu doit être structurée et normée afin que tous les intervenants manipulant la configuration de l'équipement disposent d'un référentiel de travail clair et d'une manière de procéder qui soit uniforme.
Pour cela, nous recommandons l'application des principes suivants :
1. La configuration se fait sur l'interface d'arrivée du paquet
Lorsque l'on configure des règles de filtrage sur un pare-feu, deux approches sont possibles : appliquer le filtrage lorsque le paquet réseau arrive sur le pare-feu, on parle alors de filtrage de type ingress, ou appliquer le filtrage lorsque le paquet réseau quitte le pare-feu, on parle alors de filtrage de type egress.
C'est-à-dire que pour filtrer du trafic allant, par exemple, du réseau LAN vers Internet ou le réseau WAN, la configuration doit être effectuée sur l'interface LAN.
Ce mode de fonctionnement est d'ailleurs le seul proposé sur pfSense (filtrage sur l'interface d'arrivée des paquets).
Pour être tout à fait précis, pfSense peut faire un filtrage sur l'interface de sortie du pare-feu depuis les règles de floating ; mais ce n'est clairement pas le but premier des règles de floating.
2. Il faut être le plus précis possible
Dans l'écriture des règles de filtrage, il faut toujours être le plus précis possible. Plus une règle sera précise et mieux cela sera. D'une part car l'on sera certain que seul le trafic voulu correspondra à cette règle, et d'autre part cela facilitera grandement la lecture et la compréhension des règles de filtrage.
Ainsi, dès que l'on connaît l'adresse IP, le réseau source ou le réseau destination, le port de destination, le protocole (TCP, UDP, ...), il faut le préciser dans sa règle.
Dans l'organisation de sa politique de filtrage, il est également important de classer les règles des plus précises aux plus larges.
Les règles très précises (concernant seulement quelques postes, par exemple) seront placées avant les règles plus larges (concernant tout le réseau local, par exemple).
3. Toujours préciser la source pour les interface internes
Il est important de systématiquement préciser l'adresse IP source ou le réseau source lorsque les paquets à filtrer proviennent du réseau local. En effet, dans ce cas, les adresses IP sources ou le réseau source sont connus. Il n'y a donc pas de raison de laisser la source en "any" ou *.
Pour rappel, dans les règles de filtrage de pfSense, la valeur "LAN address" correspond à l'adresse IP du firewall sur son interface LAN (192.168.1.1, par exemple) et la valeur "LAN net" correspond à tout le sous-réseau de l'interface LAN (192.168.1.0/24, par exemple).
4. Préciser la destination lorsqu'elle est connue
Dès qu'il est possible d'identifier la destination d'un flux réseau, il est important de ne pas laisser une destination générique dans ses règles de filtrage.
Par exemple, si l'on souhaite autoriser le trafic DNS à destination des serveurs Quad9, il n'y aucune raison de ne pas préciser les adresses IP des serveurs Quad9 dans la règle de filtrage associée.
De la même manière pour les envois d'e-mails, il n'y a pas de raisons d'autoriser le trafic SMTP vers une autre destination que son serveur relais de courriels.
Être le plus précis possible dans ses règles de filtrage est un gage de sécurité pour le réseau, les utilisateurs et les données.
L'utilisation d'une destination générique (any ou *) doit être réservée uniquement pour le trafic dont on ne peut réellement pas connaître la destination.
5. Utiliser des alias
L'utilisation d'alias permet un gain notable en lisibilité et permet de regrouper sur une seule règle de filtrage des adresses IP ou des ports associés.
Il est à noter que certains firewall obligent à l'utilisation d'alias dans l'écriture de leurs règles : il n'est pas possible de saisir une règle de filtrage comportant des adresses IP ou des ports réseaux ; il faut forcément qu'ils aient été préalablement renseignés dans des alias. pfSense n'impose pas ce mode de fonctionnement.
Sous pfSense, la création des alias se fait depuis le menu Firewall > Aliases :
Les alias sont à regrouper par domaine fonctionnel. On peut, par exemple, créer un alias pour le surf Web contenant les ports HTTP et HTTPS.
Exemple, sous pfSense :
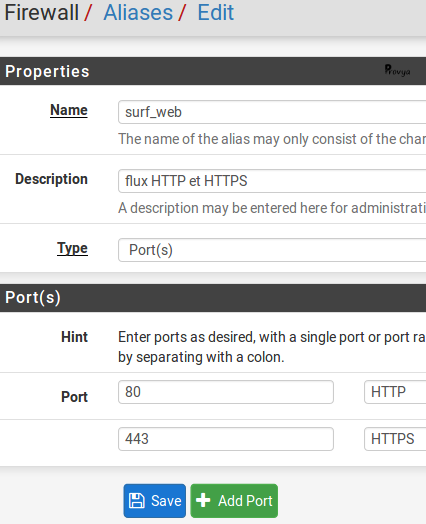
Il faudra, bien sûr, penser à sauvegarder puis appliquer les changements.
6. Ventiler et regrouper ses règles
La plupart des firewall modernes offrent la possibilité d'utiliser des séparateurs ou des couleurs pour ventiler et/ou regrouper les règles entre elles. Si votre firewall ne dispose pas de cette fonctionnalité, pensez à migrer vers pfSense. ;-)
Cette ventilation et organisation permet une plus grande lisibilité des règles et permet une administration de la solution beaucoup plus rapide.
7. Commenter, commenter, commenter
Pour conserver une compréhension de l'historique de l'implémentation des règles, il est indispensable de compléter le champ commentaire afin d'y faire figurer des informations utiles.
Dans le champ commentaire, nous pouvons par exemple faire figurer les informations suivantes :
- le succinct descriptif fonctionnel à l'origine de la création de la règle ;
- la date d'implémentation de la règle (cette information est gérée automatiquement par pfSense) ;
- la référence de la demande (n° de ticket ou code projet) ;
- le nom ou le matricule de la personne qui a créé ou modifié la règle (cette information est gérée automatiquement par pfSense, à condition que tout le monde n'utilise pas le compte "admin" par défaut...)
Ordre des règles de filtrage
Une fois les recommandations générales appliquées, nous classons nos règles de filtrage suivant l'ordre présenté ci-dessous.
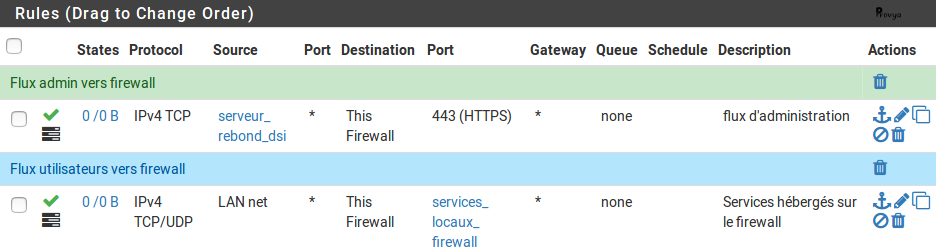
1/5. Règles d'autorisation des flux à destination du pare-feu (administration ; services hébergés sur pfSense)
Dans l'idéal, le firewall doit être administré depuis une interface dédiée. S'il ne dispose pas d'une interface dédiée, il faut, a minima, définir les adresses IP sources autorisées.
Une bonne manière de faire peut être de prendre la main sur un serveur de rebond (serveur TSE, par exemple), puis se connecter sur le firewall. Dans ce cas, seul le serveur de rebond est autorisé à accéder à l'interface d'administration du pare-feu.
Le nombre de flux ouverts doit être limité au strict minimum (HTTPS + SSH - si nécessaire - dans le cas de pfSense)
On trouvera également les règles autorisant la supervision du firewall (snmp par exemple) et les services hébergés sur le firewall (Squid, OpenVPN, DHCP, NTP, ...).
Pour ces règles, les adresses IP sources et destinations seront précisées.
On activera les logs pour ces règles afin de pouvoir retrouver a posteriori tout accès anormal ou frauduleux.
Exemple de la mise en place de ces règles pour pfSense :
2/5. Règles d'autorisation des flux émis par le pare-feu (pfSense n'est pas concerné)
On y retrouve : les règles autorisant l'envoi des logs du firewall vers le serveur de journalisation (un serveur syslog, par exemple), les règles autorisant les services d'alerte de la passerelle (alerte par e-mail, smtp, etc.), les règles autorisant les services qui permettent le MCO de la passerelle (les flux de sauvegardes - ssh par exemple).
Dans tous les cas, la destination doit être précisée (on n'utilisera pas une destination "any" ou *).
On activera les logs pour ces règles également.
/!\ pfSense n'est pas concerné par ces règles. En effet, pfSense effectue un filtrage sur les paquets arrivant sur ses interfaces. Ainsi, les paquets émis par le firewall ne sont pas filtrés.
Si l'on souhaite filtrer le trafic émis par pfSense, on peut utiliser des règles floating sur lesquelles seront appliquées un filtrage dans le sens OUT.
Attention cependant, si on applique un filtrage par ce biais, on va également filtrer le trafic issu du LAN qui aurait pris l'adresse IP du firewall (SNAT / Outbound NAT). Il faudrait alors procéder à un marquage des paquets pour identifier plus précisément leur origine. Mais ce sujet n'est pas le propos de cet article.
3/5. Règles de protection du pare-feu (règles spécifiques)
Dans la logique de tout ce qui n'est pas explicitement autorisé doit être interdit, il convient de placer une règle de filtrage interdisant tous les services depuis toutes les sources à destination de toutes les interfaces du firewall.
Cela permet de rendre le firewall invisible et bloquer tous les services inutiles.
On activera les logs pour cette règle.
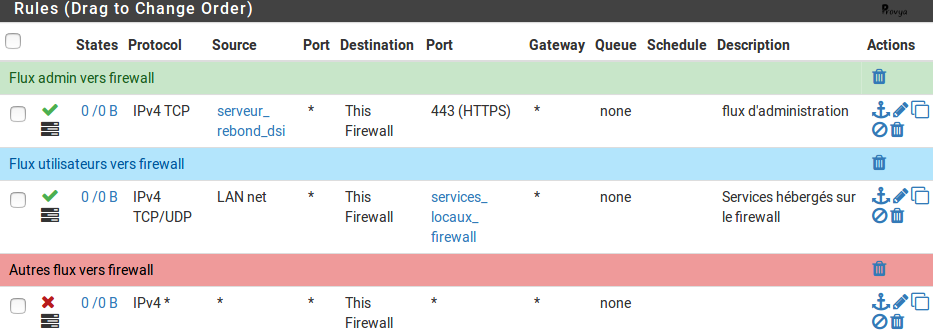
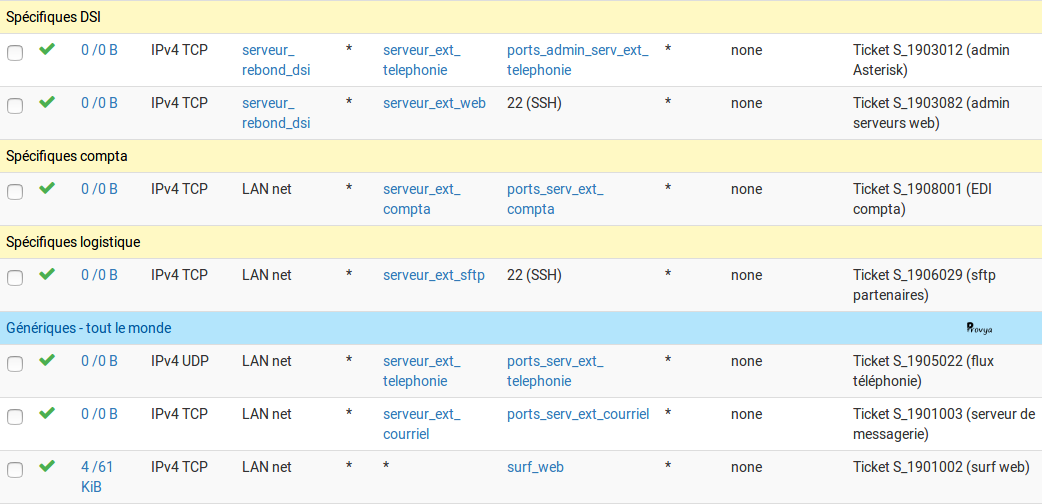
4/5. Règles d'autorisation des flux métiers
Il est recommandé d'organiser ses règles suivant une logique métier. Plusieurs approches sont possibles :
- une organisation par entité métier (regroupement des règles du service comptabilité, des ressources humaines, du service achat, etc.) ;
- une organisation par fonctions & services offerts : accès aux bases de données, accès à l'intranet, accès au serveur de messagerie, accès à Internet, etc.
Ces règles doivent être adaptées au contexte et conserver une logique entre elles (il ne faut pas passer d'une logique d'entité à une logique de fonctions en cours de route, par exemple).
Les adresses sources, destinations et les services doivent impérativement être précisés dans ces règles.
Ces règles constituent l'essentiel de la politique de filtrage.
Exemple de résultat obtenu sur un pfSense :
5/5. Règle d'interdiction finale (inutile pour pfSense)
Tout ce qui n'a pas explicitement été autorisé précédemment doit être bloqué.
C'est le mode de fonctionnement par défaut de pfSense : default deny.
Il n'est donc pas nécessaire d'ajouter une règle spécifique pour pfSense.
Par défaut, ces paquets sont loggués par pfSense, ce qui permet de garder une trace de ces flux non légitimes (ou d'aider à faire du troubleshooting en cas d'erreur ou d'anomalie dans la configuration des règles précédentes).
En appliquant cette stratégie, nous obtenons l'exemple complet suivant :
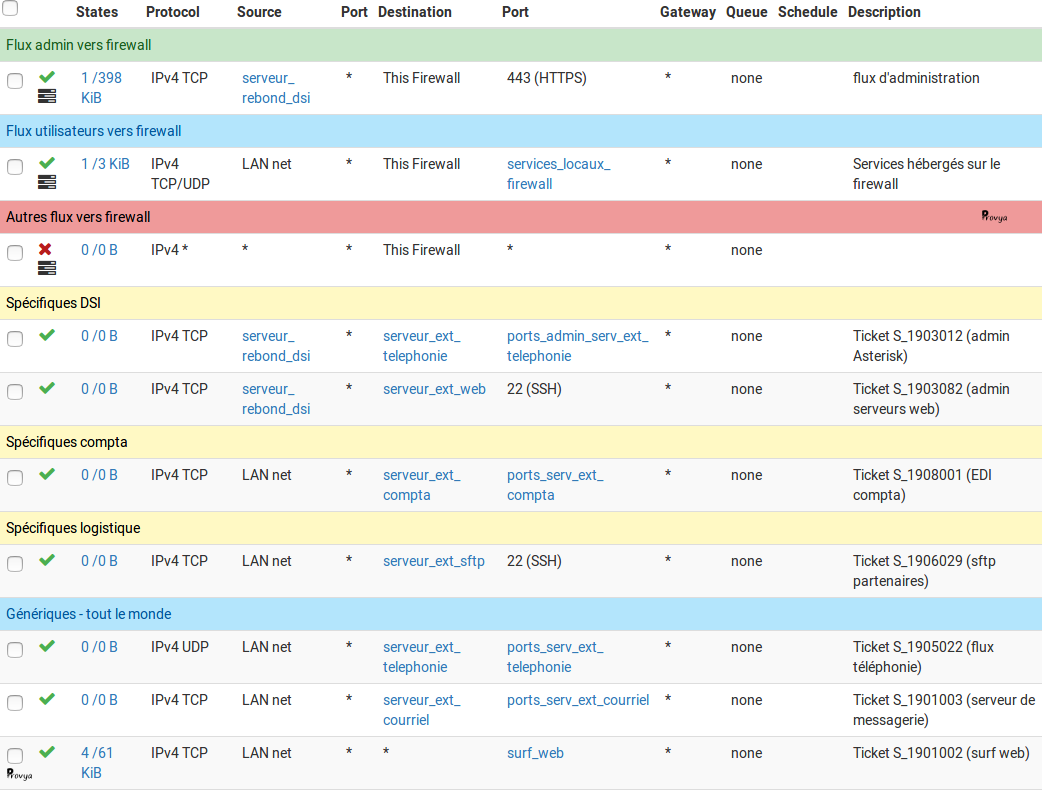
Nous vous recommandons de suivre ces principes d'organisation de vos règles de filtrage. La maintenance de votre firewall en sera facilitée, ainsi que vos sessions de troubleshooting et analyses !
Pour aller plus loin
[pfSense] Troubleshooting / Dépannage de ses règles de filtrage
[pfSense] Bien choisir et dimensionner son firewall
Tous nos articles classés par thème
Voir un article au hasard
Vous avez aimé cet article ? Vous cherchez un support professionnel ? Alors contactez-nous.
Retrouvez nos services et firewall pour pfSense





